Java Collection II - Map in Java
本文介绍Java中的Map接口以及对应的实现类。Java Collection系列第一篇整理了集合框架和Map的框架,下面两张图简单回顾一下。
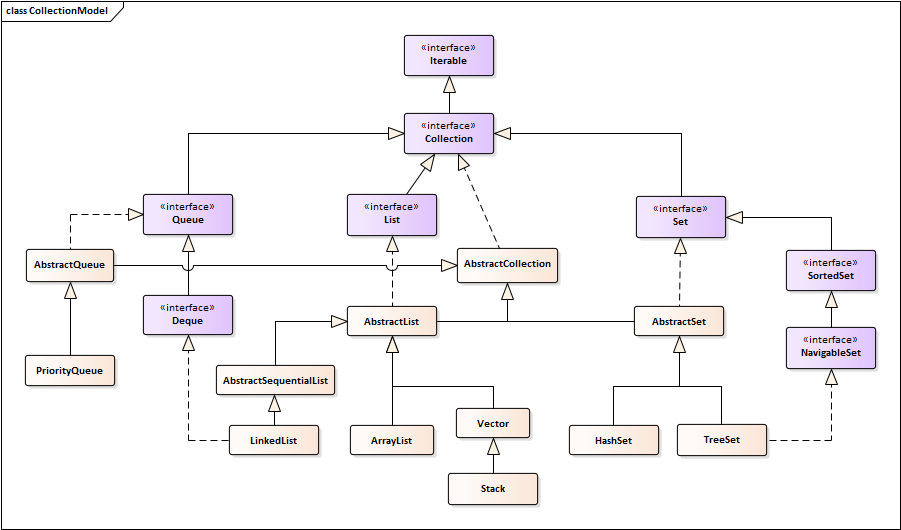
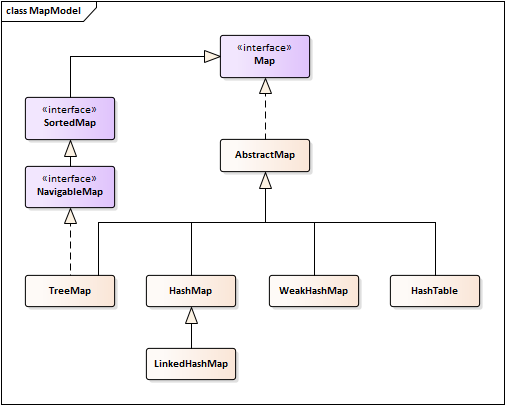
Java集合主要有List集合,Set集合,Map映射以及工具类(Arrays,Collections,Iterator),上图是继承Collection接口的类。Map是唯一一个不继承或实现Collection的集合,框架图如下。
什么是Map
Map是专为快速查找而设计的数据结构。数据在Map中以键值对的方式存储,每组键值对称为一个entry,并且不允许插入重复的键。
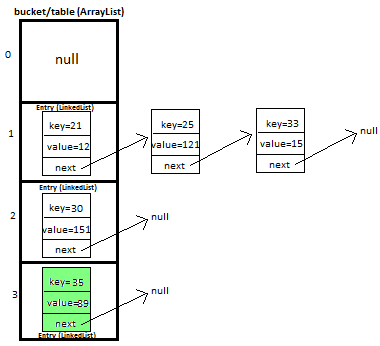
Map的实现包含TreeMap、HashMap、WeakHashMap、HashTable和LinkedHashMap,最常用的是HashMap,以下大多数的代码使用HashMap作为例子。JDK1.8中的HashMap的哈希桶采用链表和红黑树互相转化的实现,也就是当链表大小超过一定阈值的时候,会自动转化为一颗红黑树,默认阈值为TREEIFY_THRESHOLD=8。
创建Map
Map的键值类型只能是引用类型,不能使用基本数据类型。例如我们可以创建一个Integer类型的key和String类型的value的HashMap。
Map<Integer, String> map = new HashMap<>();
看了HashMap源码(JDK1.8),其构造函数共有四种,初始化的参数包含initialCapcity和loadFactor两个,分别表示HashMap的初始化大小以及容量翻倍的阈值。默认的initialCapcity值为1 << 4,默认的阈值为0.75。想知道why 0.75,可以参考so上的这个回答,大致是时间开销与空间开销的tradeoff。例如默认大小为16,当存储的entry数目超过12时,容量翻倍变为32。
我们也可以用一个Map来构造新的HashMap,需要注意的是,这里是浅拷贝。HashMap的拷贝问题本为也会提。
Map<Integer, String> map = new HashMap<>(anotherMap);
HashMap允许插入一个null键和多个null值,并且不保存元素的顺序。
基本操作
插入 HashMap的插入操作包括put,putAll以及putIfAbsent三种。
put插入一个键值对,如果map存在一个相同的key,则返回更新前的值;否则返回null;putAll与构造函数HashMap(Map<? extends K, ? extends V> m)相似,均调用putMapEntries,向当前map中插入m的所有条目;putIfAbsent则会判断是否存在相同的key,若存在则不更新对应的value;否则插入新条目;
查找 根据一个key获取HashMap存储的对应的value的方法有get和getOrDefault两种。
get返回对应的value或者null;- 而
getOrDefault函数在key不存在的情况下返回一个默认值;
删除 remove函数则会删除相应的<key,value>条目,并且返回value;如果key不存在则返回null。在删除的过程中,函数会判断要删除的节点是普通Node还是TreeNode。如果是TreeNode,删除完成后会根据阈值判断是否要还原为链表结构。
集合视图 Map接口提供了根据集合类型查看Map内部元素的方法使得我们可以遍历map。
- keySet(),返回map中的所有键
- values(),返回map中的所有值
- entrySet(),返回所有<key,value>条目
Map的遍历
map的遍历方式有很多种,这里我们列举几种常用的方式。
foreach与entrySet
entrySet视图经常用来遍历一个map,这里要注意map不能为null,否则会报NullPointerException。这种方法效率高。
for(Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
Lambda表达式
Java 8中引入了Lambda表达式,一种更紧凑的遍历写法可以是下面这样的:
map.forEach((k,v) -> System.out.println(k + ": " + v));
Iterator迭代器
所有实现Collection接口的集合都实现了迭代器接口。我们可以获取entrySet的迭代器,利用迭代器对map进行遍历。迭代器可以似乎用带泛型和不带泛型的,这里贴以下使用泛型的代码。
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while(it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
System.out.println(entry.getKey() + ": " + entry.getValue());
}
Map的排序
HashMap并不会为entries保留一个顺序,若要使得所有条目按照key排序,可使用TreeMap。TreeMap是基于红黑树实现的映射,它可以根据key的自然排序为所有entries保留顺序,也可以在构造的时候提供默认的Comparator。get/put/containsKey的时间复杂度为$\log{n}$。与HashMap一样,TreeMap也是线程不安全的,若要在多线程环境使用,需要在外部做好线程同步操作。
Map<Integer, String> map = new TreeMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.forEach((k, v) -> System.out.println(k + ": " + v));
输出是按照key排序的:
1: A
2: B
3: C
我们也可以把所有条目按value进行排序,利用Collections工具类提供的sort方法和按value重写的Comparator可以实现。例如可以封装一个函数,返回一个按value排序的map。
private static <K extends Comparable, V extends Comparable> Map<K, V> sortMapByValue(Map<K, V> map) {
List<Map.Entry<K, V>> entries = new LinkedList<>(map.entrySet());
Collections.sort(entries, new Comparator<Map.Entry<K, V>>() {
@Override
public int compare(Map.Entry<K, V> o1, Map.Entry<K, V> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
Map<K, V> sortedMap = new LinkedHashMap<>();
for(Map.Entry<K, V> entry : entries) {
sortedMap.put(entry.getKey(), entry.getValue());
}
return sortedMap;
}
浅拷贝与深拷贝
浅拷贝跟深拷贝的概念这里不再赘述,可以参见维基百科(Object copy)。假设我们有一个Student类。
public class Student {
private String name;
// constructor, getters and setters
}
Shallow copy
前面提到HashMap利用其他map作为参数的构造函数是一种浅拷贝的方式。另外还可以利用Map.clone()和Java 8提供的Stream API。
Set<Entry<String, Student>> entries = originalMap.entrySet();
HashMap<String, Student> shallowCopy = (HashMap<String, Student>) entries.stream()
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
Deep copy
目前为止,Java并没有提供内建的深拷贝的实现,可以借助第三方的库,用序列化反序列化的方式实现。例如使用Apache Commons Lang提供的SerializationUtils。首先我们的Student类必须是实现Serializable接口的,改写为:
public class Student implement Serializable {
private String name;
// constructor, getters and setters
}
HashMap<String, Student> deepCopy = SerializationUtils.clone(originalMap);
算法题
同构字符串
本题是LeetCode简单难度205题,要求判断给定的两个字符串是否是同构字符串。
给定两个字符串
s与t,判断它们是否是同构的。同构是说,如果我们可以把s中的某些字母替换掉得到t,那么他们就是同构的。 Example:
Input:s="egg",t="add"
Output: true
根据同构定义,只需要s与t相同下标的值的映射是一致的即可,例如g与d一直是对应的。这样我们可以遍历s,保存相应的值的映射,如果发现一个不一致的映射则返回false。很容易想到用HashMap。
class Solution {
public boolean isIsomorphic(String s, String t) {
if(s == null || s.isEmpty()) return true;
int p = 0;
HashMap<Character, Character> map = new HashMap<>();
while(p < s.length()) {
if(map.containsKey(s.charAt(p))) {
if(!map.get(s.charAt(p)).equals(t.charAt(p))) return false;
}
else {
if(!map.containsValue(t.charAt(p))) {
map.put(s.charAt(p), t.charAt(p));
}
else return false;
}
++p;
}
return true;
}
}
最长协调子序列
LeetCode简单难度594题,要求在给定数组中找到最长的协调子序列。
我们成一个数组为协调数组如果它的最大值和最小值的差正好为1。现在给定一个数组,请在所有可能的子序列中找到一个最长的协调子序列。 Example:
Input: [1,3,2,2,5,2,3,7]
Output: 5
Note: 最长协调子序列为[3,2,2,2,3]
最直接的做法是对数组进行排序,然后双指针遍历排序后的数组,找到所有协调子数组,输出长度最长的即可。
class Solution {
public int findLHS(int[] nums) {
Arrays.sort(nums);
int len = 0;
int left = 0, right = 1;
while(right < nums.length) {
while(left < nums.length && nums[right] - nums[left] > 1) ++left;
if(nums[right] - nums[left] == 1) len = Math.max(right-left+1, len);
++right;
}
return len;
}
}
由于本文讨论Map,这里也给出Map的解法。算法思想是,先一趟遍历数组,用map记录每个整数出现的次数。然后第二趟遍历数组,对于每个元素n,记录n与n+1出现的次数,次数之和即为一个协调子序列的长度。
class Solution {
public int findLHS(int[] nums) {
Map<Integer, Integer> map = new HashMap<>();
for(int n : nums) {
map.put(n, map.getOrDefault(n, 0)+1);
}
int res = 0;
for(int n : nums) {
if(map.containsKey(n+1)) {
res = Math.max(res, map.get(n)+map.get(n+1));
}
}
return res;
}
}
算法时间复杂度$O(n)$,空间开销也为$O(n)$。